


In the ever-evolving landscape of SEO, canonical tags stand as unsung heroes, silently steering search engines away from potential pitfalls of duplicate content.
These seemingly modest snippets of code wield mighty power, ensuring your content retains its rightful place in the digital hierarchy.
In this article, we will cover everything you need to know about canonical tags and their importance for SEO:
- What are canonical tags?
- Why are canonical tags important in SEO?
- How to implement canonical tags?
- Canonical tags best SEO practices
- Common canonical tag mistakes
- How to check canonical tags?
What is a canonical tag?
A canonical tag (or rel=canonical) is a small piece of HTML code that helps search engines to identify the “main” version of a page from the rest of the pages that are identical or very similar to it.
In SEO, canonical tags are used to let Google know which version of a page you would prefer to appear in search results. Additionally, canonical tags can help you consolidate link equity from duplicate pages and improve the overall crawling and indexing of your website.
Here’s what a canonical tag might look like on a webpage:
<link rel="canonical" href="https://mangools.com/blog/robots-txt/" />
For example, suppose you have published an article on your blog with a specific URL, and a few other blogs want to display the same content on their own pages or URLs.
In this case, you need to implement canonical tags on their pages. These canonical tags should point to the URL of your original, main version of the article.
By doing this, you effectively indicate to search engines that your page is the authoritative source, ensuring the original content gets the appropriate credit and reducing the risk of duplicate content issues.
Why are canonical tags important in SEO?
The primary purpose of the canonical tag is to inform search engines which page is the main, original version and which pages are duplicates containing the same content.
Generally, websites often contain pages that can be considered duplicates of each other – they display the same content but have different URLs.
In these instances, Google has to decide which page from the set of identical web pages should be used for indexing and ranking purposes – the search engine won’t use all the pages as search results since they all look identical or just very similar.
For example, a product page in an online store might not be displayed with just one main URL. The page can be shown to users with various parameters often used by e-commerce websites (e.g. for due to filters for sorting, currency, sizes, etc.):
https://www.randomshop.com/clothes/shirts/ https://www.randomshop.com/clothes/shirts/?Size=XL https://www.randomshop.com/clothes/shirts/?Size=XL&color=red
In this example, the product page can be displayed in the main category /clothes/ and with the URL slug /shirts/. However, it can also appear with URL parameters (e.g. when an online store user filters products on the website by size and color). Therefore, the product web page can be actually displayed as a search result under 3 different URLs.
This is where canonical tags became important – they will indicate to Google that you want to index the main URL category /clothes/, use it as a search result and ignore the other URLs.
Note: Keep in mind that Google perceives canonical tag as a signal, not as a directive.
If there are valid reasons to choose another page for indexing and ranking purposes over the canonical one, the search engine might ignore the canonical tag altogether.
Or as Martin Splitt stated:
“All right, let’s start with the idea that it is a directive because it’s not.”
Besides the fundamental purpose of the canonical tag, there are also some important SEO benefits that come with it.
1. They consolidate PageRank
Canonical tags help to consolidate link equity (PageRank) from all duplicate pages into the one main, canonical page.
Duplicate pages can often obtain backlinks from various external sources – whether they are backlinks from random websites, posts on social media, forums, etc.
These pages therefore partially “steal” the link juice value from the main version of the page – the one you actually want to rank as a search result.
By implementing canonical tags on the duplicate pages, you can transfer PageRank other important ranking signals to a single URL and therefore improve its overall ranking in Google Search.
2. They help manage syndicated content
Canonical tags can inform search engines which website hosts the original version of the content and which sites are just republishing or syndicating it.
Many website owners use external websites for publishing their content – either for promotional, informational or other purposes.
In such cases, Google has to decide which website is the original source of the content and should be displayed as a search result in SERPs and which websites are simply promoting it.
Setting up canonical tags on these external websites helps to resolve this problem and promote the original, main version of the page in Google Search.
3. They improve crawling
Canonical tags help search engines like Google to efficiently crawl pages that you actually want to be indexed and ranked – as opposed to duplicates that should not be used by the search engine at all.
Duplicate pages waste Google’s resources and time as they are not important for crawling or indexing purposes.
By appointing canonical pages on your website, Google can concentrate on the pages that matter most, save the “crawl budget”, and ultimately rank your pages faster in SERPs.
Or as Google officially stated:
“The canonical page will be crawled most regularly; duplicates are crawled less frequently in order to reduce Google crawling load on your site.”
How to implement canonical tags?
Adding canonical tags to your pages is pretty straightforward – simply go to any duplicate webpage and add rel="canonical" tag into the <head> section of the page.
The link in the canonical tag should point to the main, original version.
Implementing canonical tags is ideally done on a page-by-page basis. However, this can be time-consuming and resource-intensive, or might be even impossible to do for larger websites.
Fortunately, canonical tags can also be implemented automatically or through other methods, such as:
- Using an SEO plugin
- Using HTTP header
Use an SEO plugin
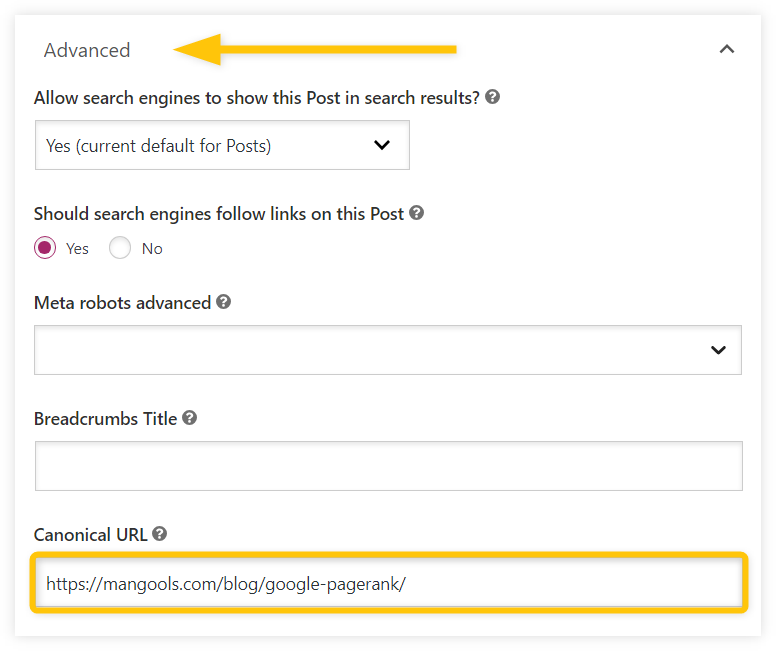
Canonical tags can be also implemented automatically using various SEO plugins, such as Yoast SEO (for WordPress).
The implementation process with this plugin is quite simple:
- Select the page for canonicalization.
- Head over to the “Advanced” section of the page.
- Add the canonical URL to which you wish to refer.
Use HTTP header
Canonical tags can be also added in the HTTP header of the webpage.
This is particularly useful for special non-HTML documents such as PDFs since they don’t contain any <head> section where a standard canonical tag could be placed.
To implement canonical tags in the HTTP header, you need to access the .htaccess file of your site and add the canonical tag in a format similar to this:
Link: <https://www.yoursite.com/random-document.pdf>; rel="canonical"
If you would like to learn more about adding canonical tags via the HTTP header, check out this article on the implementation of canonical tags.
Tip: There are also a few other ways on how you can tell the search engine about pages which pages you wish to designate as canonical versions:
- Sitemap – Google can automatically assume that all the URLs listed in the sitemap are the main, canonical versions.
- Redirects – duplicate pages can transfer traffic and page signals to a single, canonical URL using 301 redirects.
- Internal linking – Google can more easily identify canonical pages if internal links within your site consistently point to them from duplicate pages.
- HTTPS – search engines like Google often prefer pages with a valid SSL certificate (HTTPS) as canonical, over pages without encryption (HTTP).
Canonical tag best SEO practices
1. Use self-referencing canonicals
Although not mandatory, it is always a good practice to add a canonical tag to a page that points to itself – even if you haven’t used canonical tags on the rest of the duplicate pages.
Using self-referencing rel=canonical tag on the main, original pages gives search engines like Google a clear signal that they are canonical versions:
“I recommend doing this kind of self-referential rel=canonical because it really makes it clear for us which page you want to have indexed or what this URL should be when it’s indexed.” (John Mueller).
2. Use absolute URLs
Using absolute URLs in canonical tags can help avoid unintentional mistakes or misinterpretations of canonical URLs by search engines, as opposed to using relative URLs.
Absolute URLs should also include “https“, “//“, “www“, and trailing slashes (if possible).
Here is an example of an absolute URL in a canonical tag:
<link rel="canonical" href="https://www.randomwebsite.com/randompage/" />
And here is an example of a relative URL:
<link rel="canonical" href="/randompage/" />
3. Use lowercase URLs
Search engines like Google can be sensitive to uppercase and lowercase letters in URLs.
Using lowercase in canonical URLs can help maintain consistency and avoid duplication issues from the perspective of search engines.
As a good SEO practice, try to use lowercase letters in URLs on your servers and apply them to the canonical tags.
4. Canonicalize cross-domain duplicates
Canonical tags can reference your main pages from other domains, not just from your own website.
If you have duplicate content on pages hosted on different websites (e.g. a repurposed post on a news site), you should:
- Use a self-referencing canonical tag on your original page.
- Apply a canonical tag on the external page, referencing your original one.
What to avoid with canonical tags?
1. Multiple canonicals on a single page
Pay attention to the multiple canonical tags that might accidentally appear in a page’s HTML.
Although rare, having more than one canonical tag on a page can confuse search engines and lead to the canonical signals being ignored.
Or as Google officially stated:
“In cases of multiple declarations of rel=canonical, Google will likely ignore all the rel=canonical hints. Any benefit that a legitimate rel=canonical might have offered will be lost.”
2. Avoid canonicals on non-duplicates
Always ensure that the content on duplicate pages and the main version of the page is either identical or at least very similar when applying canonical tags.
Implementing canonical tags on pages that are completely different might confuse search engines or cause the canonical tags to be completely ignored.
Or as Martin Splitt explained:
“… if the content is completely different or different enough for the algorithms to decide that this is not a duplication, then the canonical is pointless.”
3. Canonicals on paginated pages
Paginated pages contain fragmented content spread across several pages (e.g. a comment section on a website divided into pages “1,” “2,” “3,” etc.).
In this instance, you should always use self-referencing canonical tags on each individual page, rather than referring all pages back to page “1.”
“The main thing to avoid, since this post is about canonicalization, is to use the rel=canonical on page 2 pointing to page 1. Page 2 isn’t equivalent to page 1, so the rel=canonical like that would be incorrect.” (John Mueller)
4. Avoid blocking canonical tags via robots.txt
You should never block URLs with canonical tags using the robots.txt file.
Robots.txt will prevent Google from crawling the duplicate pages and therefore it will be unable to see the canonical tag referencing the main version of the page.
Additionally, blocking URLs that contain canonical tags will also prevent PageRank from being transferred to your main versions.
5. Don’t use canonical tags in the <body>
Canonical tags should always be applied in the <head> section of your pages, not in any other part of the HTML document.
If placed in the <body> section or elsewhere, Google will simply ignore the canonical tags.
6. Avoid canonical loops and chains
Always use canonical tags that reference directly to the main page to avoid canonical loops (similar to the redirect loops).
For example, using a canonical tag from page A to page B, and then from page B to page C, creates a canonical chain that can confuse search engines and waste their resources and time.
How to check and audit canonical tags?
Check canonical tags manually
The most straightforward way how to check the canonical tag on the web page is simply reviewing the HTML document of the page manually. To do this, you can simply:
- Right-click on the page within your browser.
- Select “View page source” (or simply press Ctrl + U).
- Press “Ctrl + F” and type “canonical”.
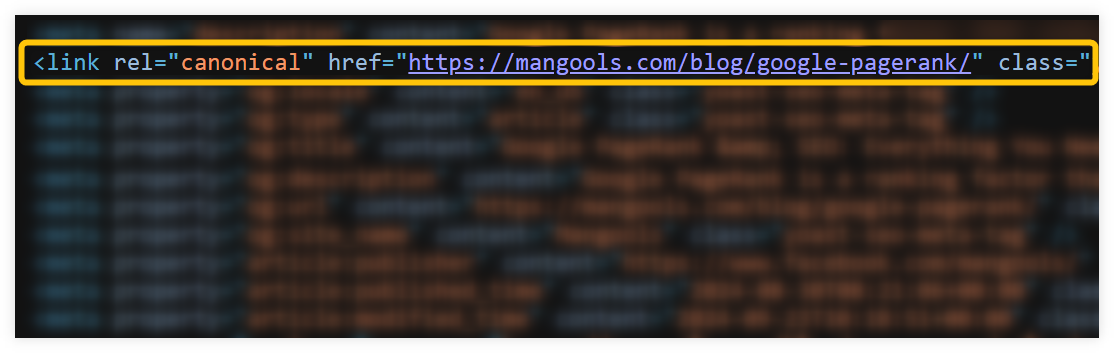
This method should allow you to find the canonical tag on your page within a few seconds. However, it may be challenging or inefficient depending on the page’s structure and HTML complexity.
Use Google Search Console
You can verify whether your canonical tags have been implemented properly and how Google perceives them directly in your Google Search Console (GSC) account.
If you want to check a specific page, you can enter the URL into the GSC search bar (URL inspection tool) at the top:
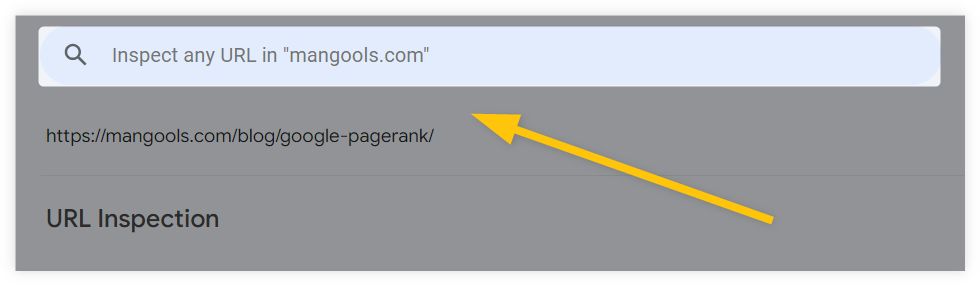
The URL inspection tool will then display all the important crawling and indexing data about the page, along with information on whether the page contains a canonical tag and if Google recognizes the canonical version.
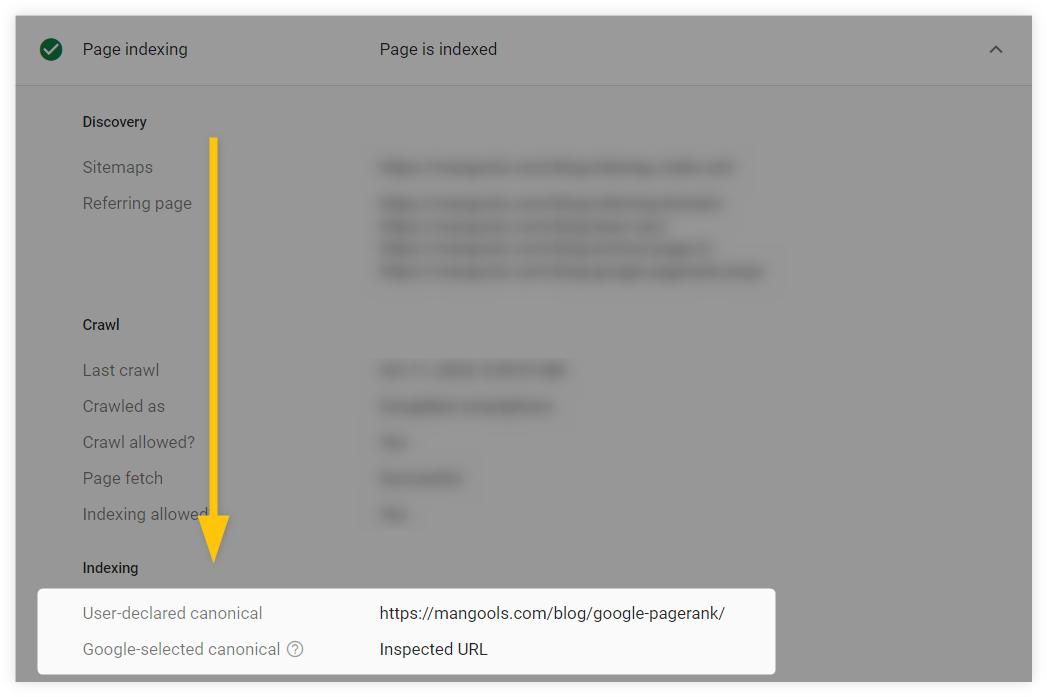
Another way to check if your canonical tags are implemented properly and to identify any duplicate URL issues on your website is through the “Indexing” section in Google Search Console. Simply:
- Click on the “Pages” tab on the left.
- Find and select the “Duplicate without user-selected canonical” option.
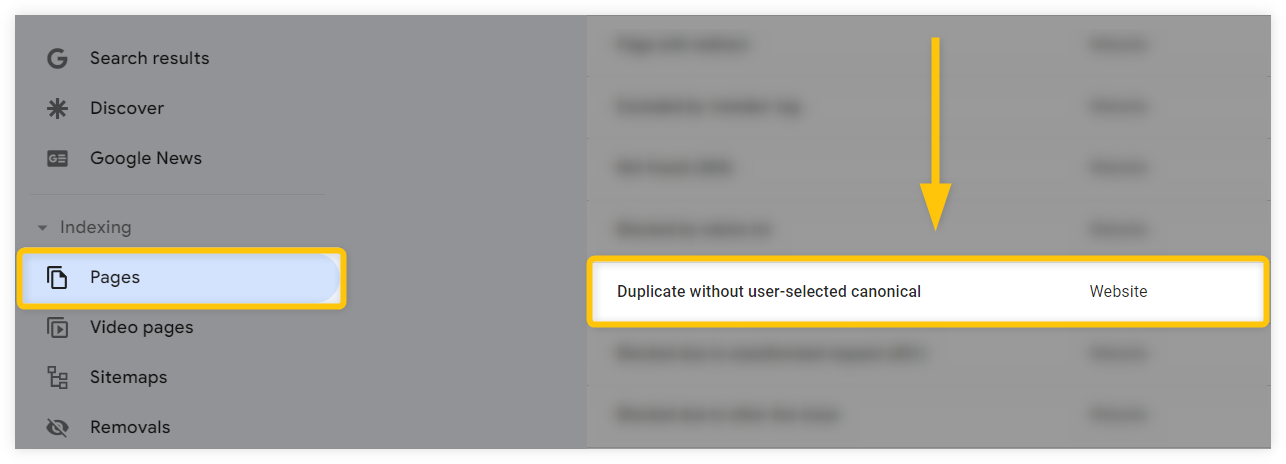
Google Search Console will then show you all URLs on your website that do not have canonical tags pointing to the main versions.
Try Mangools SEO extension
Mangools free SEO extension can help you check whether or not any of your page on your website contain canonical tags just in a matter of clicks. All you need to do is:
- Click on the “On-page SEO” tab at the top of the extension.
- Select “SERP Presence” from the bar on the left.
- Scroll down and check the “Canonical link.”
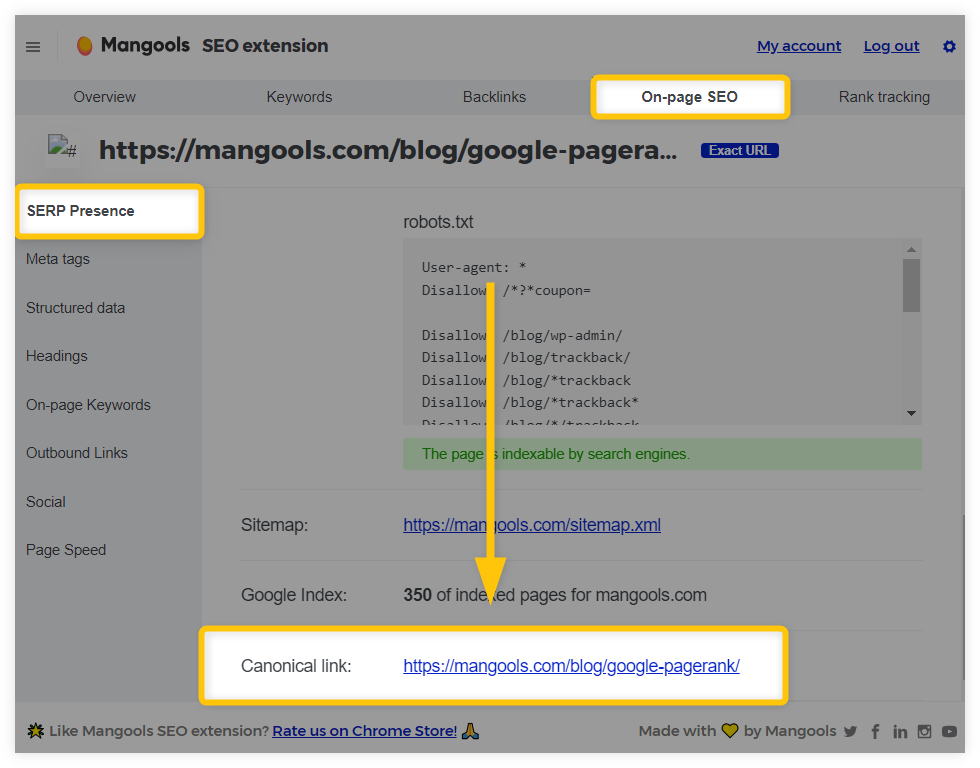
Our SEO extension will show you the link specified within the canonical tag (i.e., which page is designated as the canonical version) or if the canonical tag is present and not empty.
Besides checking canonical tags, you can use the Mangools SEO extension for many other important aspects of on-page SEO. Our web extension provides various crucial SEO data about your page, such as:
- Structured data
- On-page SEO tags (title tag, meta description, meta tags, etc.)
- Heading structure (H1 tag, H2s, H3s, etc.)
- Outbound links
- Page speed
- Overall link strength and authority of the website
