What is crawling?
Crawling is a process that allows search engines to discover new content on the internet. To do this, they use crawling bots that follow links from the already known webpages to the new ones.
Since thousands of webpages are produced or updated every day, the process of crawling is a never-ending mechanism repeated over and over again.
Martin Splitt, Google Webmaster Trend Analyst, describes the crawling process quite simply:
“We start somewhere with some URLs, and then basically follow links from thereon. So we are basically crawling our way through the internet (one) page by page, more or less.”
Crawling is the very first step in the process. It is followed by indexing, ranking (pages going through various ranking algorithms) and finally, serving the search results.
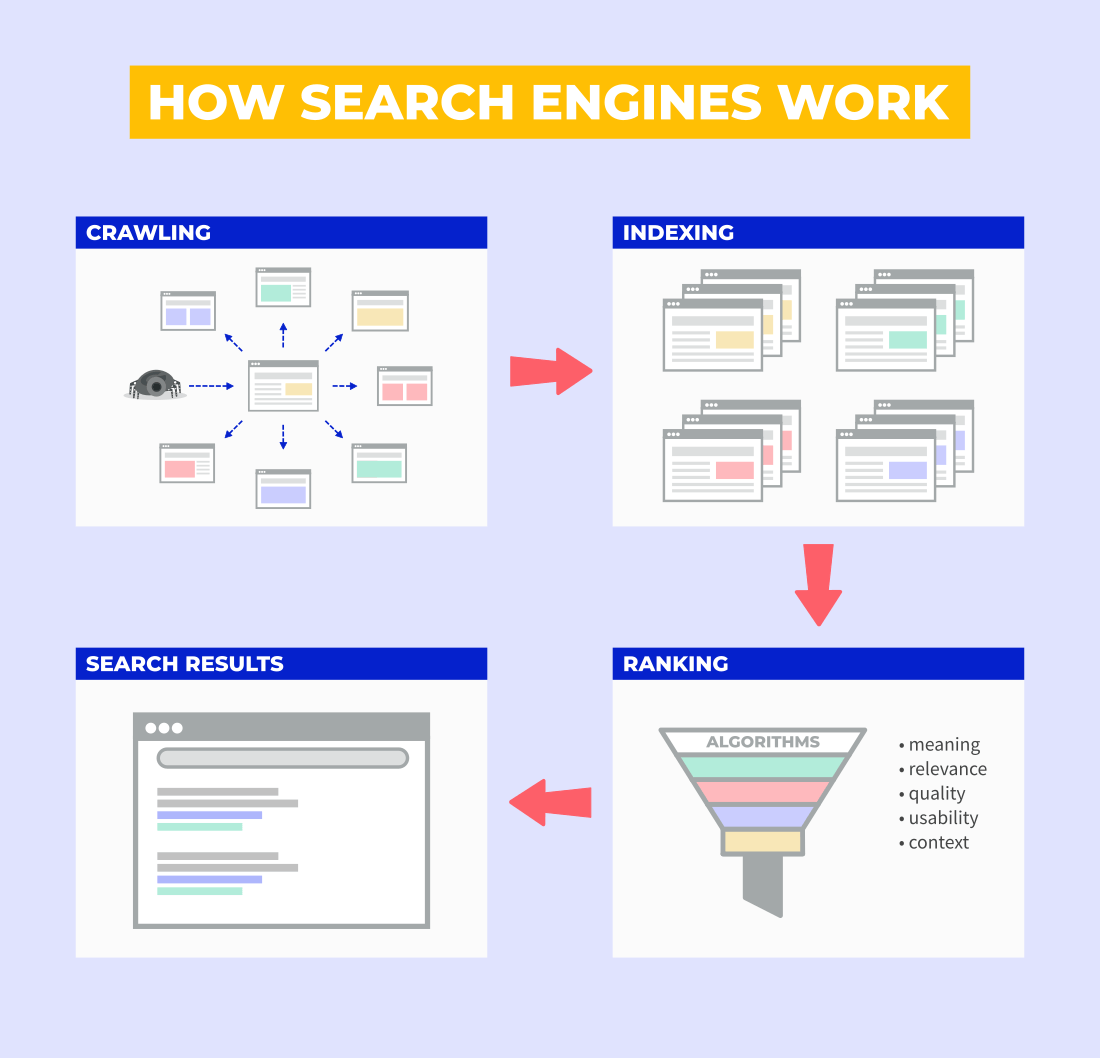
Let’s go a little bit deeper here and take a look at how crawling works.
What is a search engine crawler?
Search engine crawler (also called web spider or crawl bot) is a piece of program that crawls webpages, scans their content and collects the data for indexing purposes.
Whenever a crawler visits a new webpage via a hyperlink, it looks at the content it contains – scanning all the text, visual elements, links, HTML, CSS or JavaScript files etc. – and then passes (or fetches) this information for processing and eventual indexing.
Google, as a search engine, uses its own web crawler called Googlebot. There are 2 main types of crawlers:
- Googlebot Smartphone – primary crawler
- Googlebot Desktop – secondary crawler
Googlebot prefers to crawl websites primarily as a smartphone browser, but it can also re-crawl every webpage with its desktop crawler to check how the website performs and behaves from both perspectives.
The crawling frequency of new pages is determined by the crawl budget.
What is a crawl budget?
Crawl budget determines the amount and the frequency of crawling performed by web spiders. In other words – it dictates how many pages will be crawled and how often will those pages be re-crawled by Googlebot.
Crawl budget is determined by 2 main factors:
- Crawl rate limit – the number of pages that can be crawled simultaneously on the website without overloading its server.
- Crawl demand – the number of pages that need to be crawled and/or recrawled by Googlebot.
Crawl budget should be mostly of concern for large websites with millions of webpages, not for small sites that contain just a few hundreds of pages.
In addition, having a large crawl budget does not necessarily provide any extra benefits to a website since it is not a signal of quality for search engines.
What is indexing?
Indexing is a process of analyzing and storing the content from the crawled webpages into the database (also called index). Only the indexed pages can be ranked and used in the relevant search queries.
Whenever a web crawler discovers a new webpage, Googlebot passes its content (e.g. text, images, videos, meta-tags, attributes, etc.) into the indexing phase where the content is parsed for a better understanding of the context and stored in the index.
Martin Splitt explains what the indexing stage actually does:
“Once we have these pages (…) we need to understand them. We need to figure out what is this content about and what purpose does it serve. So then that’s the second stage, which is indexing.”
To do this, Google uses the so-called Caffeine indexing system that was introduced in 2010.
The database of a Caffeine index can store millions and millions of gigabytes of webpages. These pages are systematically processed and indexed (and re-crawled) by Googlebot according to the content they contain.
Googlebot not only visits websites by mobile crawler first, but it also prefers to index content present on their mobile versions since the so-called Mobile-First Indexing update.
What is Mobile-First Indexing?
Mobile-first indexing was first introduced in 2016 when Google announced that they will primarily index and use content available on the website’s mobile version.
Google’s official statement makes it clear:
“In mobile-first indexing, we will only get the information of your site from the mobile version, so make sure Googlebot can see the full content and all resources there.”
Since most people use mobile phones to browse the internet today, it makes sense that Google wants to look at the websites “in the same way” as people do. It is also a clear appeal to web owners to make sure their websites are responsive and mobile-friendly.
Note: It is important to realize that mobile-first indexing does not necessarily mean that Google won’t crawl websites with its desktop agent (Googlebot Desktop) to compare the content of both versions.
At this point, we’ve covered the concept of crawling and indexing from the theoretical perspective.
Now, let’s take a look at actionable steps that you can perform when it comes to the crawling and/or indexing of your website.
How to get Google to crawl and index your website?
When it comes to actual crawling and indexing, there is no “direct command” that would make search engines to index your website.
However, there are several ways to influence if, when or how your website will be crawled and indexed.
So let’s check what your options are when it comes to “telling Google about your existence”.
1. Just do nothing – passive approach
From a technical point of view, you don’t have to do anything to get your website crawled and indexed by Google.
All you need is one link from the external website and Googlebot will eventually start crawling and indexing all the pages available.
However, taking a “do nothing” approach can cause a delay in crawling and indexing of your pages since it can take some time for a web crawler to discover your website.
2. Submit webpages via URL Inspection tool
One of the ways how you can “secure” crawling and indexing of individual webpages is to directly ask Google to index (or re-index) your pages by using the URL Inspection Tool in Google Search Console.
This tool comes in handy when you have a brand new page or you made some substantial changes to your existing page and want to index it as soon as possible.
The process is quite simple:
1. Go to Google Search Console and insert your URL into the search bar at the top. Click enter.
2. Search Console will show you the status of the page. If it’s not indexed, you can request indexing. If it’s indexed, you don’t have to do anything or request again (if you made any bigger changes to the page).
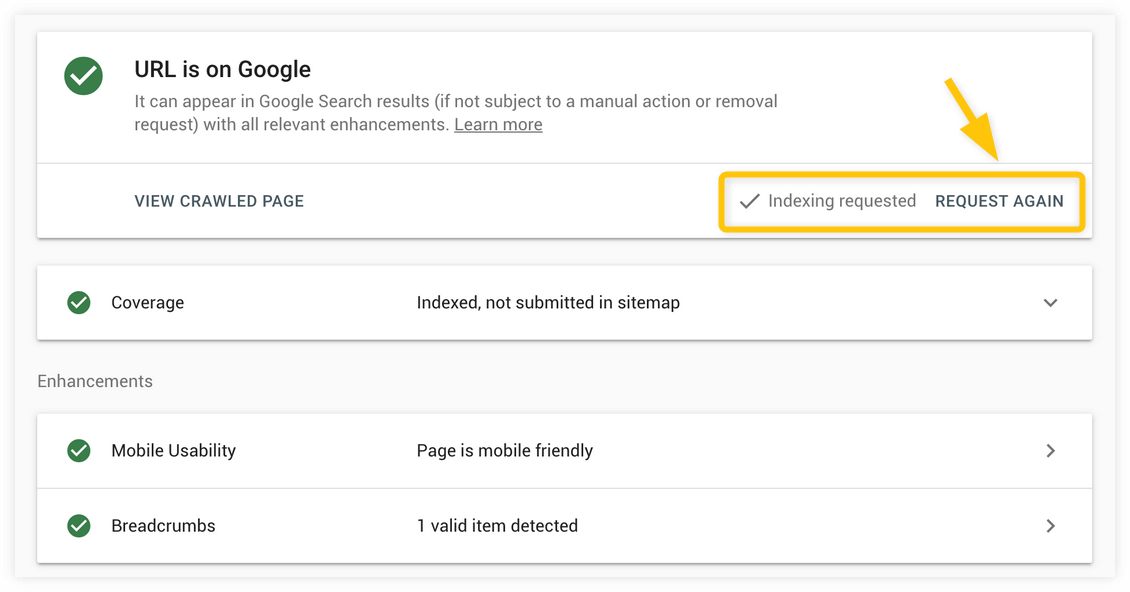
3. URL inspection tool will start testing whether the live version of the URL can be indexed (it can take a few seconds or minutes).
4. Once the testing is successfully done, a notification will pop up, confirming that your URL was added to a priority crawl queue for indexing. The indexing process can take up from a few minutes to several days.
Note: This method of indexing is recommended for just a few webpages; do not abuse this tool if you have a large number of URLs that you want to index.
The request for indexing does not necessarily guarantee that your URL will be indexed. If the URL is blocked for crawling and/or indexing or has some quality issues which are contradicting with Google’s quality guidelines, the URL might not get indexed at all.
3. Submit a sitemap
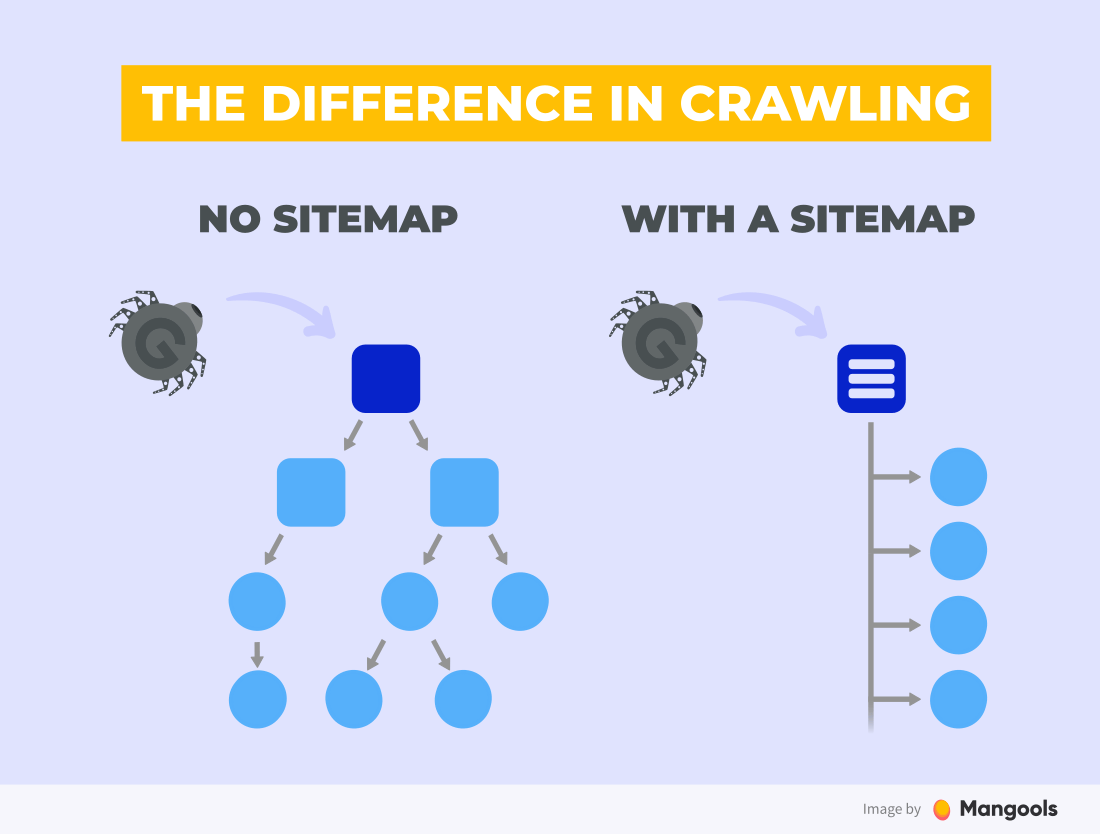
A sitemap is a list or a file in the XML format that contains all your webpages you intend to be crawled and indexed by the search engine.
The main benefit of sitemaps is that makes it much easier for a search engine to crawl your website. You can submit a huge number of URLs at once and therefore speed up the overall indexing process of your website.
To let Google know about your sitemap, you’ll use Google Search Console again.
Note: The easiest way to create a sitemap for your WordPress website is to use the Yoast SEO plugin that will do it for you automatically. Check this guide to learn how to find the URL of your sitemap.
Then go to Google Search Console > Sitemaps and paste the URL of your sitemap under Add a new sitemap:
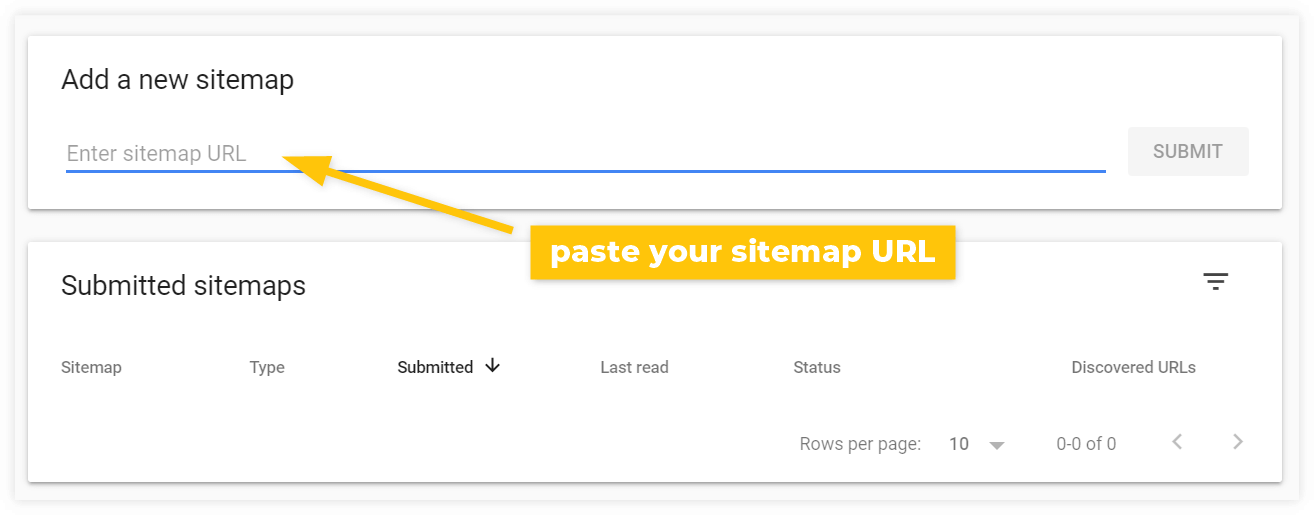
After the submission, Googlebot will eventually check out your sitemap and crawl every listed webpage you provided (assuming they are not prevented from crawling and indexing in any way).
4. Do proper internal linking
A strong internal linking structure is a great long-term approach to making your webpages easy to crawl.
How to do that? The answer is a flat website architecture. In other words, having all the pages less than 3 links from each other:
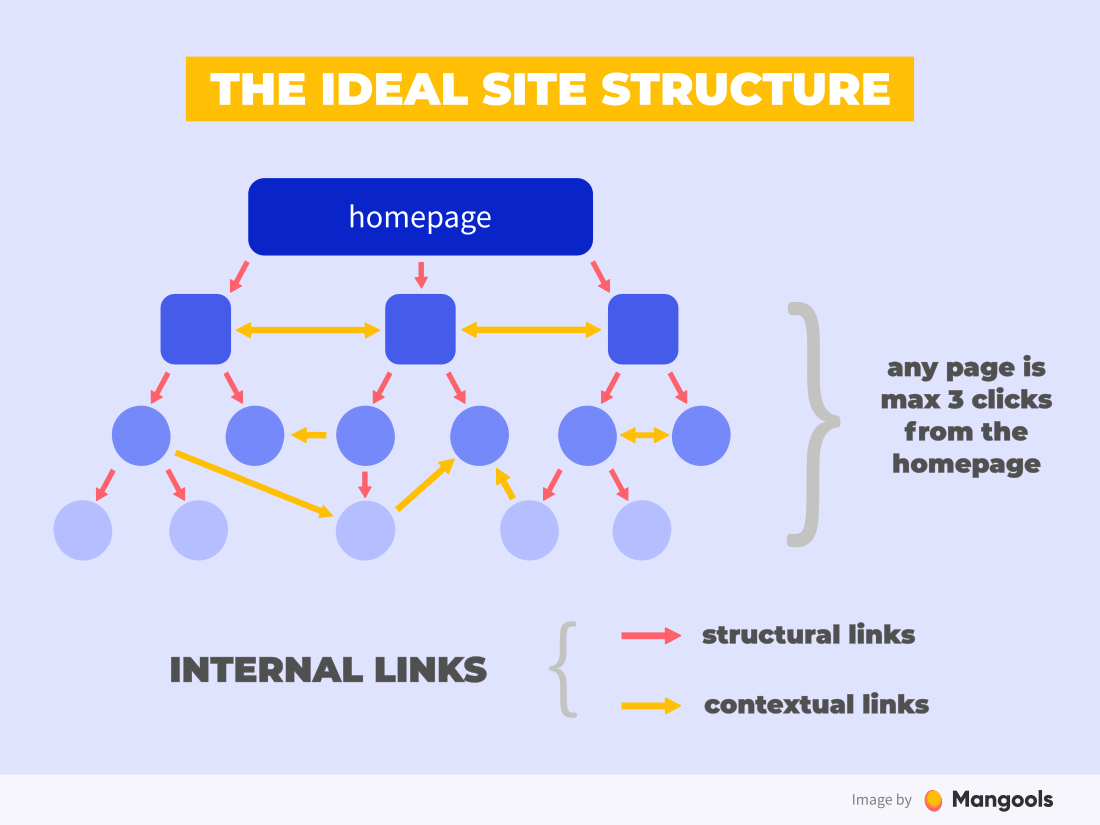
A good linking architecture can secure crawling of all webpages that you want to be indexed since web crawlers will have easy access to all of them. This practice is especially important for large sites (e.g. e-commerce) that contain thousands of pages with products.
Tip: Internal linking is important but you should also aim at getting strong and relevant external links from high authority websites. It can result in regular crawling and indexing as well as higher rankings in relevant SERPs.
How to prevent Google from crawling and indexing your page?
There are many reasons to prevent Googlebot from crawling and/or indexing parts of your website. For example:
- Private content (e.g. user’s information which should not appear in search results)
- Duplicate webpages (e.g. pages with the identical content which should not be crawled for saving crawl budget and/or appearing in search results multiple times)
- Empty or error pages (e.g. work-in-progress pages which are not prepared to be indexed and shown in search results)
- Little-to-no-value pages (e.g. user-generated pages that do not bring any quality content for search queries).
At this point, it should be clear that Googlebot is very efficient when it comes to discovering new webpages even when it was not in your intention.
As Google states: “It’s almost impossible to keep a web server secret by not publishing links to it.”
Let’s take a look at our options when it comes to the prevention of crawling and/or indexing.
1. Use robots.txt (to prevent crawling)
Robots.txt is a small text file that contains direct commands for web spiders about how they should crawl your website.
Whenever web crawlers visit your website, they first check whether your website contains robots.txt file and what the instructions are for them. After reading the commands from the file, they start crawling your website as they were instructed.
By using the “allow” and “disallow” directives in the robots.txt file, you can tell web crawlers what parts of the website should be visited and crawled and what webpages should be left alone.
Here’s an example of the New York Times’s website robots.txt file with many disallow commands:
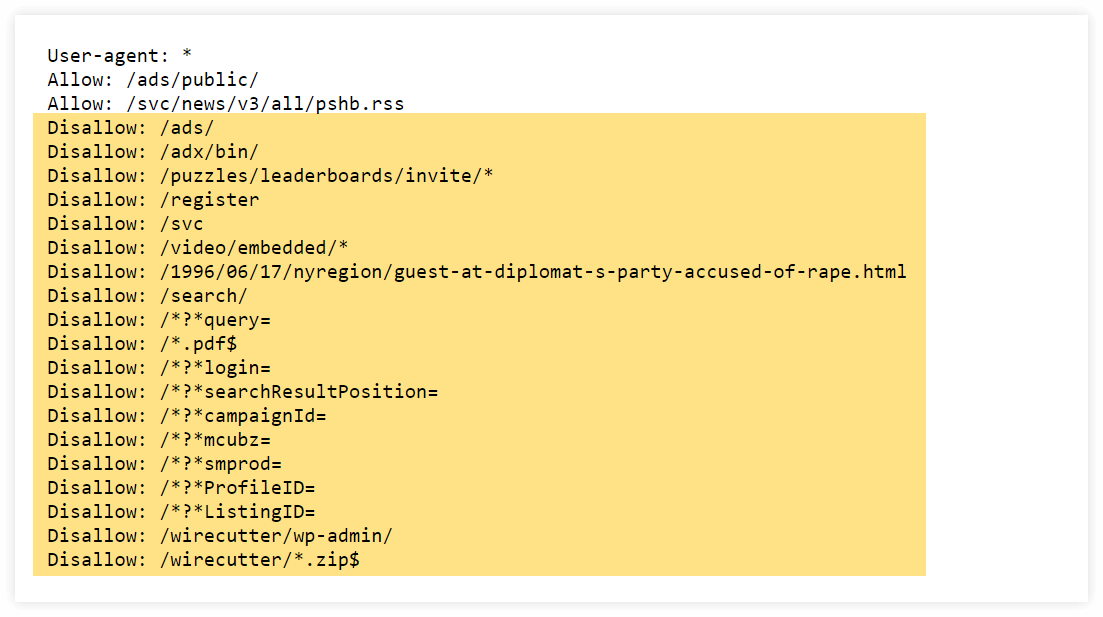
For example, you can prevent Googlebot from crawling:
- pages with duplicate content
- private pages
- URLs with query parameters
- pages with thin content
- test pages
Without instructions from this file, the web crawler would visit every webpage it can find, including URLs that you want to avoid from being crawled.
Although robots.txt can be a good way on how to prevent Googlebot from crawling your pages, you should not rely on this method as a way to hide content.
Disallowed webpages can still be indexed by Google if some other websites are pointing links to these URLs.
To prevent webpages from being indexed, there is another, more efficient method – Robots Meta Directives.
2. Use the “noindex” directive (to prevent indexing)
The robot meta directives (sometimes called meta tags) are small pieces of HTML code put in the <head> section of a webpage that instruct search engines how to index or crawl that page.
One of the most common directives is the so-called “noindex” directive (a robot meta directive with the noindex value in the content attribute). It prevents search engines from indexing and showing your webpage in the SERPs.
It looks like this:
<meta name="robots" content="noindex">
The “robots” attribute means that the command applies to all types of web crawlers.
The noindex directive is especially useful for pages that are intended to be seen by visitors but you don’t want them to be indexed or appear in the search results.
The noindex is usually combined with the follow or nofollow attributes to tell search engines whether they should crawl the links on the page.
Important: You should not use both noindex directive and robots.txt file to block web crawlers from accessing your page.
As Google clearly stated:
“For the noindex directive to be effective, the page must not be blocked by a robots.txt file. If the page is blocked by a robots.txt file, the crawler will never see the noindex directive, and the page can still appear in search results, for example if other pages link to it.”
How to check whether the page is indexed?
When it comes to checking whether the webpages are crawled and indexed or if a particular webpage has some issues, there are a few options.
1. Check it manually
The easiest way to check whether your website was indexed or not is to do it manually by using the site: operator:
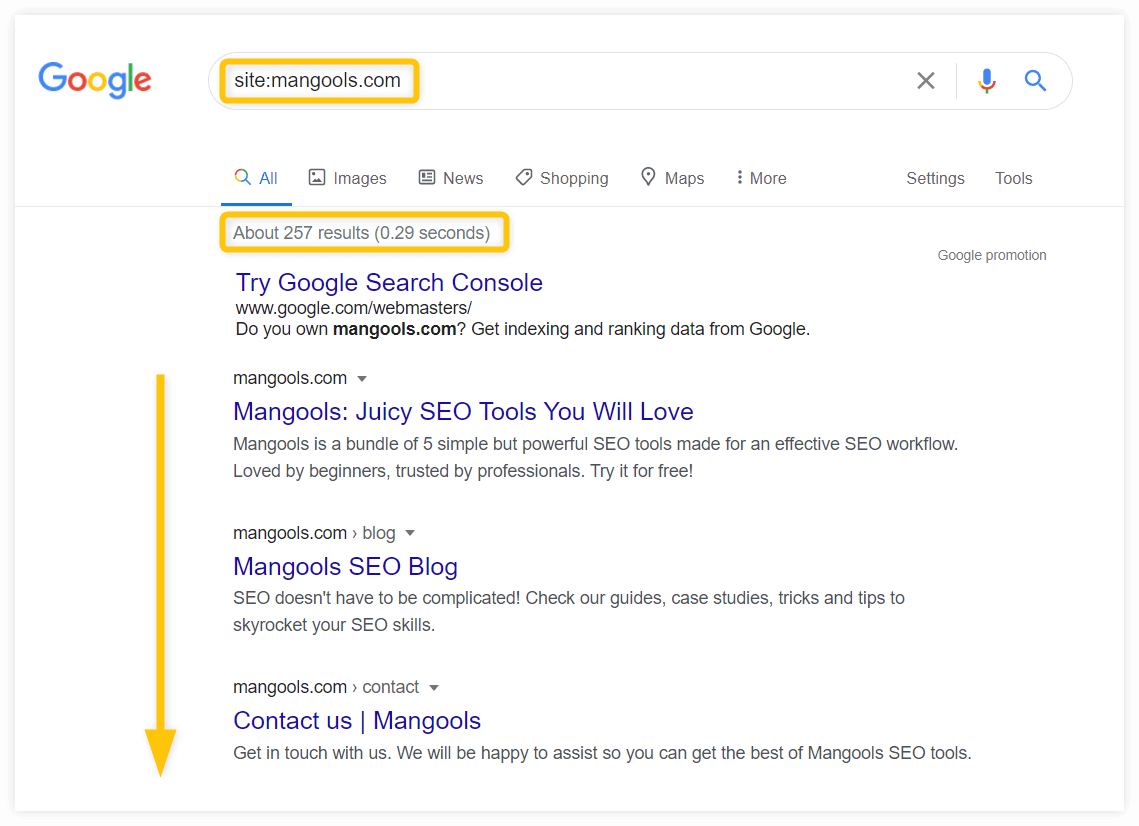
If your website was crawled and indexed, you should see all the indexed pages as well as the approximate number of indexed pages in the “About XY results” section.
If you would like to check whether a specific URL has been indexed, use the URL instead of the domain:
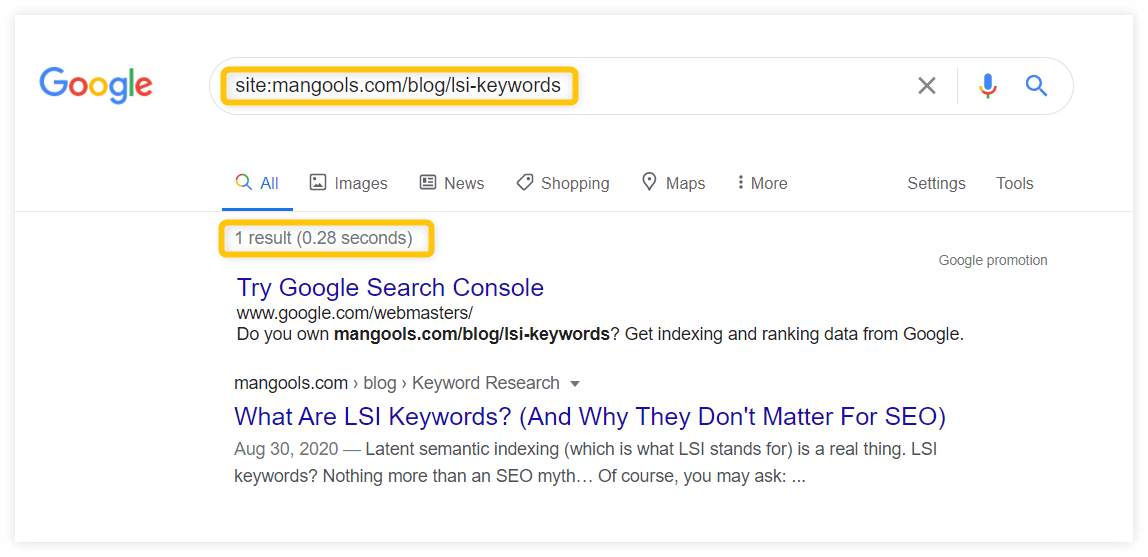
If your webpage was indexed, you should see it in the search results.
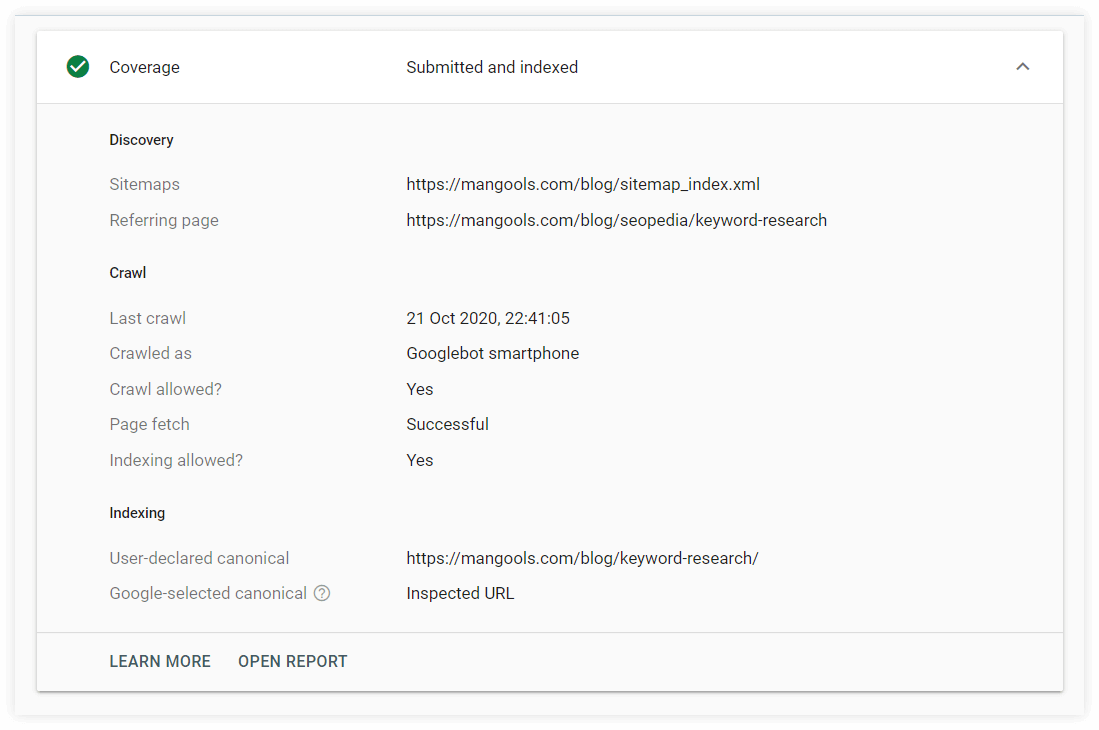
2. Check Index Coverage Status
To get a more detailed overview of your indexed (or not indexed) pages, you can use the Index Coverage Report in Google Search Console.
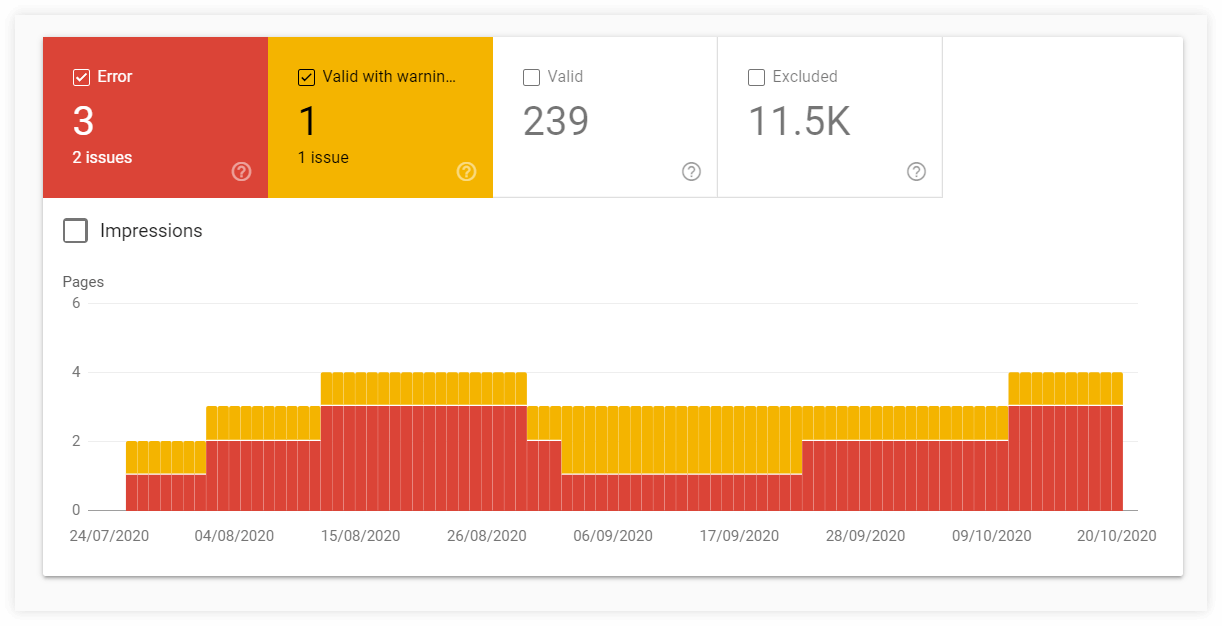
Charts with details within the Index Coverage Report can provide valuable information about statuses of URLs and types of issues with crawled and/or indexed pages.
3. Use the URL Inspection tool
The URL Inspection tool can provide information about individual webpages within your website from the last time they were crawled.
You can check out whether your webpage:
- has some issues (with details about how it was discovered)
- was crawled and the last time of crawling
- whether the page is indexed and can appear in search results