

What is a robots.txt file?
Robots.txt is a short text file that instructs web crawlers (e.g. Googlebot) what they are allowed to crawl on your website.
From the SEO perspective, robots.txt helps to crawl the most important pages first and prevents bots from visiting pages that are not important.
Here’s how robots.txt can look like:

Where to find robots.txt
Finding robots.txt files is pretty straightforward – go to any domain homepage and add “/robots.txt” at the end of it.
It will show you a real, working robots.txt file, here’s an example:
https://yourdomain.com/robots.txt
Robots.txt file is a public folder that can be checked practically on any website – you can even find it on sites such as Amazon, Facebook, or Apple.
Why is robots.txt important?
The purpose of the robots.txt file is to tell crawlers which parts of your website they can access and how they should interact with the pages.
Generally speaking, it is important that the content on the website can be crawled and indexed first – search engines have to find your pages before they can appear as search results.
However, in some instances, it is better to ban web crawlers from visiting certain pages (e.g. empty pages, login page for your website, etc.).
This can be achieved by using a robots.txt file that is always checked by crawlers first before they actually start crawling the website.
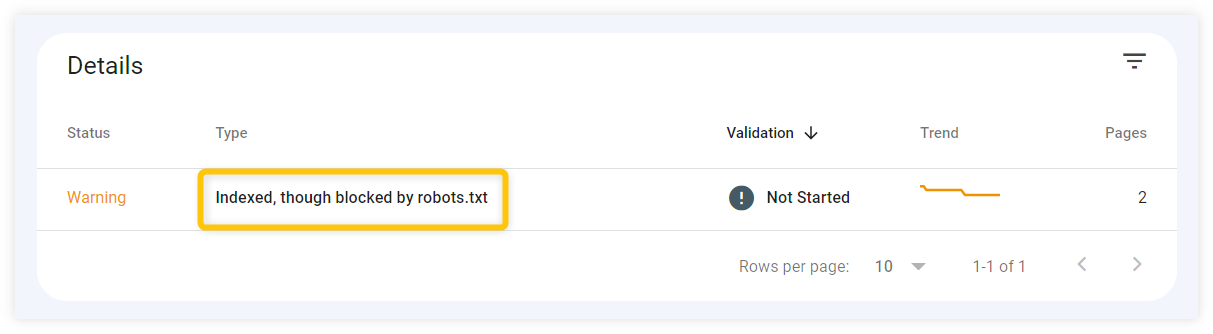
Note: Robots.txt file can prevent search engines from crawling, but not from indexing.
Although crawlers might be prohibited from visiting a certain page, search engines might still index it if some external links are pointing to it.
This indexed page can therefore appear as a search result, but without any useful content – since crawlers couldn’t crawl any data from the page:

To prevent Google from indexing your pages, use other suitable methods (e.g. noindex meta tag) for indicating that you don’t want some parts of your website to appear as search results.
Besides the fundamental purpose of the robots.txt file, there are also some SEO benefits that might be useful in certain situations.
1. Optimize crawl budget
The crawl budget determines the number of pages that web crawlers such as Googlebot will crawl (or re-crawl) within a certain period.
Many larger websites usually contain tons of unimportant pages that do not need to be frequently (or not at all) crawled and indexed.
Using robots.txt tells search engines which pages to crawl, and which to avoid altogether – which optimizes the efficiency and frequency of crawling.
2. Manage duplicate content
Robots.txt can help you avoid the crawling of similar or duplicate content on your pages.
Many websites contain some form of duplicate content – whether there are pages with URL parameters, www vs. non-www pages, identical PDF files, etc.
By pointing out these pages via robots.txt, you can manage content that does not need to be crawled and help the search engine to crawl only those pages that you want to appear in Google Search.
3. Prevent server overload
Using robots.txt might help prevent the website server from crashing.
Generally speaking, Googlebot (and other respectable crawlers) are usually good at determining how fast they should crawl your website without overwhelming its server capacity.
However, you may wish to block access to crawlers that are visiting your site too much and too often.
In these instances, robots.txt can tell crawlers on which particular pages they should be focusing on, leaving other parts of the website alone and thus preventing site overload.
Or as Martin Splitt, the Developer Advocate at Google explained:
“That’s the crawl rate, basically how much stress can we put on your server without crashing anything or suffering from killing your server too much.”
In addition, you may wish to block certain bots that are causing site issues – whether that is a “bad” bot overloading your site with requests, or block scrapers that are trying to copy all your website’s content.
How does the robots.txt file work?
The fundamental principles of how robots.txt file work is pretty straightforward – it consists of 2 basic elements that dictate which web crawler should do something and what exactly that should be:
- User-agents: specify which crawlers will be directed to avoid (or crawl) certain pages
- Directives: tells user-agents what they should do with certain pages.
Here is the simplest example of how the robots.txt file can look like with these 2 elements:
User-agent: Googlebot Disallow: /wp-admin/
Let’s take a closer look at both of them.
User-agents
User-agent is a name of a specific crawler that will be instructed by directives about how to crawl your website.
For example, the user-agent for the general Google crawler is “Googlebot”, for Bing crawler it is “BingBot”, for Yahoo “Slurp”, etc.
To mark all types of web crawlers for a certain directive at once, you can use the symbol ” * ” (called wildcard) – it represents all bots that “obey” the robots.txt file.
In the robots.txt file, it would look like this:
User-agent: * Disallow: /wp-admin/
Note: Keep in mind that there are many types of user-agents, each of them focusing on crawling for different purposes.
If you would like to see what user-agents Google use, check out this overview of Google crawlers.
Directives
Robots.txt directives are the rules that the specified user-agent will follow.
By default, crawlers are instructed to crawl every available webpage – robots.txt then specifies which pages or sections on your website should not be crawled.
There are 3 most common rules that are used:
- “Disallow” – tells crawlers not to access anything that is specified within this directive. You can assign multiple disallow instructions to user-agents.
- “Allow” – tells crawlers that they can access some pages from the already disallowed site section.
- “Sitemap” – if you have set up an XML sitemap, robots.txt can indicate web crawlers where they can find pages that you wish to crawl by pointing them to your sitemap.
Here’s an example of how robots.txt can look like with these 3 simple directives:
User-agent: Googlebot Disallow: /wp-admin/ Allow: /wp-admin/random-content.php Sitemap: https://www.example.com/sitemap.xml
With the first line, we have determined that the directive applies to a specific crawler – Googlebot.
In the second line (the directive), we told Googlebot that we don’t want it to access a certain folder – in this case, the login page for a WordPress site.
In the third line, we added an exception – although Googlebot can’t access anything that is under the /wp-admin/ folder, it can visit one specific address.
With the fourth line, we instructed Googlebot where to find your Sitemap with a list of URLs that you wish to be crawled.
There are also a few other useful rules, that can be applied to your robots.txt file – especially if your site contains thousands of pages that need to be managed.
* (Wildcard)
The wildcard * is a directive that indicates a rule for matching patterns.
The rule is especially useful for websites that contain tons of generated content, filtered product pages, etc.
For example, instead of disallowing every product page under the /products/ section individually (as it is in the example below):
User-agent: * Disallow: /products/shoes? Disallow: /products/boots? Disallow: /products/sneakers?
We can use the wildcard to disallow them all at once:
User-agent: * Disallow: /products/*?
In the example above, the user-agent is instructed to not crawl any page under the /products/ section that contains the question mark “?” (often used for parameterized product category URLs).
$
The $ symbol is used to indicate the end of a URL – crawlers can be instructed that they shouldn’t (or should) crawl URLs with a certain ending:
User-agent: * Disallow: /*.gif$
The “ $ “ sign tells bots that they have to ignore all URLs that end with “.gif“.
#
The # sign serves just as a comment or annotation for human readers – it has no impact on any user-agent, nor does it serve as a directive:
# We don't want any crawler to visit our login page! User-agent: * Disallow: /wp-admin/
How to create a robots.txt file
Creating your own robots.txt file is not rocket science.
If you are using WordPress for your site, you will have a basic robots.txt file already created – similar to the ones shown above.
However, if you plan to make some additional changes in the future, there are a few simple plugins that can help you manage your robots.txt file such as:
These plugins make it easy to control what you want to allow and disallow, without having to write any complicated syntax by yourself.
Alternatively, you can also edit your robots.txt file through FTP – if you are confident in accessing and editing it, then uploading a text file is pretty easy.
However, this method is a lot more complicated and can quickly introduce errors.
Tip: If you would like to know more about uploading robots.txt file to your website, check out Google’s documentation about creating and uploading a robots.txt file.
How to check a robots.txt file
There are many ways how you can check (or test) your robots.txt file – firstly, you should try to find robots.txt on your own.
Unless you have stated a specific URL, your file will be hosted at “https://yourdomain.com/robots.txt” – if you are using another website builder, the specific URL might be different.
To check whether search engines like Google can actually find and “obey” your robots.txt file, you can either:
- Use robots.txt Tester – a simple tool by Google that can help you find out whether your robots.txt file functions properly.
- Check Google Search Console – you can look for any errors that are caused by robots.txt in the “Coverage” tab of Google Search Console. Make sure that there are no URLs that are reporting messages “blocked by robots.txt” unintentionally.
Robots.txt best practices
Robots.txt files can easily get complex, so it is best to keep things as simple as possible.
Here are a few tips that can help you with creating and updating your own robots.txt file:
- Use separate files for subdomains – if your website has multiple subdomains, you should treat them as separate websites. Always create separated robots.txt files for each subdomain that you own.
- Specify user-agents just once – try to merge all directives that are assigned to a specific user-agent together. This will establish simplicity and organization in your robots.txt file.
- Ensure specificity – make sure to specify exact URL paths, and pay attention to any trailing slashes or specific signs that are present (or absent) in your URLs.
