
What is an XML Sitemap?
An XML sitemap is a structured list of all pages on a website available to be crawled by search engines. The XML sitemap is not intended to be viewed by users as it is written in a machine-readable format. It is used in the form of an XML file containing data marked up with tags. XML stands for “extensible markup language” – a file format agreed to be used for sitemaps.
Search engine crawler bots can find your pages in two ways:
- By visiting all the links found on a page and repeating this for every visited page
- By visiting the pages listed in the sitemap
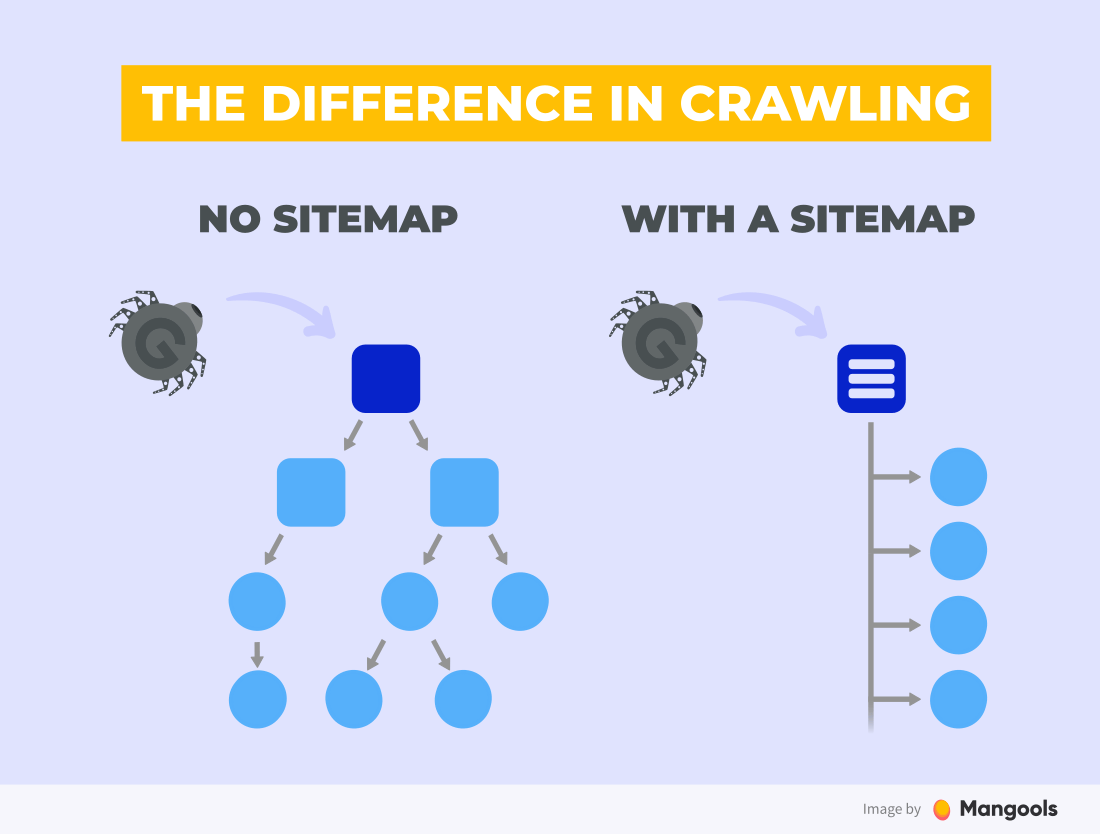
A sitemap is supplemental to the normal crawling of the web. However, the first option not always works. For example, the search engines won’t be able to find and index a page that isn’t linked from any other page. This is one case when a sitemap comes to the rescue.
What types of XML sitemaps do we know?
URL Sitemap – this is what most people refer to with/as “XML sitemap”. It lists URLs of the pages on your website.
Sitemap Index – a “sitemap of sitemaps”. It lists all your sitemaps if you have more than one. For example, you might have different sitemaps for posts and pages (common with WordPress websites) or multiple sitemaps if one of them exceeds the size limit. You will also need multiple sitemaps if you are over the sitemap size or number of URLs limit.
Media Sitemap – you can create a separate sitemap for your images and videos or you can include them in your normal URL sitemap.
Do I need an XML sitemap?
The great thing is, you can only benefit from having a sitemap. There are no risks in having one.
Google claims that “in most cases, your site will benefit from having a sitemap, and you’ll never be penalized for having one.”
But is implementing a sitemap worth the extra work?
A blog with hundreds of well-structured pages with a good internal linking probably won’t see any difference in the number of indexed pages, because all of them were probably indexed even before having a sitemap.
Which websites should definitely use a sitemap?
Huge websites
If you have a website with thousands of pages (e.g. online shop), it’s great to let the search engines know about all your URLs available for crawling. To make crawling more efficient (which is especially important for big websites), you should include the last updated metadata in the sitemap.
Websites with poorly interlinked pages
If you know your website has poor internal linking, and some of the pages might be “orphans” without any internal or external links, it’s great to have a sitemap to inform the search engines about their existence.
New websites without any backlinks
If you’ve just started a blog and your domain is still nowhere to be found in the SERP, the easiest way to catch crawlers’ attention is to submit your website and your XML sitemap to Google Search Console and Bing Webmaster tools.
There’s more to the sitemap than being indexed by the search engines.
For example, a sitemap can speed up the whole process of crawling. How? It can contain important additional information for each URL.
What information can a sitemap carry?
Sitemaps can (but don’t have to) carry valuable information (metadata) for search engines. The most common sitemap metadata are:
1. Date of the last update of the page (lastmod attribute)
This is one of the most valuable pieces of information for search engines. Instead of crawling the page and checking if anything has changed (and thus spending precious resources and CPU time), it can just check the last updated field in the sitemap and do the simple math:
Crawler: The last time I crawled this page was March 1, 2019. The sitemap tells me the page has been last updated on February 14, 2019. I don’t have to waste my time crawling and indexing this unchanged page and will rather spend my time crawling pages that have changed since my last visit.
It’s a win-win situation. Your page will get crawled sooner, and the search engines will save resources that would otherwise be spent on recrawling and comparing your pages. As a result, search engines have a fresher index of websites.
You may think: “Okay, so I will make a script to update all the lastmod attributes in my sitemap to a new date every day and my site will always be super fresh in Google.” Don’t do that, it won’t help.
Google only uses the lastmod attribute when used properly.
“When we can tell that it’s used properly, it’s a useful signal. One of the problems I see often is that sites use the Date/time of when the sitemap was generated as the last-modification date for all of the Pages in the sitemap file – that isn’t useful.” John Mueller explained in this Reddit thread.
“Sitemaps may help webmasters with two current challenges: keeping Google informed about all of your new web pages or updates, and increasing the coverage of your web pages in the Google index.” – Google Blog
So, to recap, a crawler can prioritize crawling of freshly updated pages, and not spend resources on recrawling unchanged pages (e.g. privacy policy page).
2. How often is a page updated (changefreq attribute)
This one is tricky. At first, it seems like just another information for search engines to improve their crawling optimization. But isn’t it a bit redundant?
Yes, it is! In reality, the date of the last update is a much better indicator if a website needs to be recrawled. That’s why all the major search engines are ignoring this attribute.
As John Mueller explained in this video:
“It is much better to just specify the time stamp directly so that we can look into our internal systems and say we haven’t crawled since this date, therefore we should crawl again.” The video is from 2015, but John confirmed the information again in his 2019 tweet:
yeah, we use lastmod (generally), but not changefreq or priority afaik.
— John #InternalLinkBuilder #ProfileTextEditor (@JohnMu) March 6, 2019
3. How important a page is (priority attribute)
It sounds like a good way of informing search engines of the most important pages on my website, doesn’t it? Well, here’s what John Mueller from Google has to say about this:
We ignore priority in sitemaps.
— John #InternalLinkBuilder #ProfileTextEditor (@JohnMu) August 17, 2017
Other search engines might still use the priority attribute, but further details are not known. Here are the 3 most probable uses of the priority attribute:
- High priority pages might get crawled more often
- If two pages match the same query, the page with a higher priority might be the one displayed in the search results
- If a website is new, higher priority pages might get indexed first
A much better way of calculating the priority of each page on your website is to take a look at internal links. Pages with most (and most prominent) internal links are likely to be the most important. That’s why Google ignores the priority attribute altogether.
4. Presence of an alternative language version
Declaring hreflang alternatives directly in the code for each page can be a pain for websites with thousands of pages. Luckily, you can declare all your language mutations in one XML sitemap file. For more details, check out the official sitemap hreflang guide from Google.
XML sitemap file requirements
A sitemap can either be a plain text list of URLs (not recommended) or it can use the sitemap protocol and make use of XML tags (the best way to do it). It must be UTF-8 encoded and can be compressed in gzip format (highly recommended).
The maximum file size is 50 MB (whether compressed or not) or 50,000 URLs.
If you want to include more than 50,000 pages in the sitemap, you just have to split it into two or more sitemap files and create a sitemap index that will link to all those sub-sitemaps.

Automatically generated sitemap index from the YoastSEO WordPress plugin.
The same applies to the 50 MB size limit. If you exceed the max limit, you will have to split your sitemap into multiple sitemaps linked from the main sitemap index.
If all of this is too technical for you and your website runs on WordPress, use a plugin (like Yoast SEO) that will do the job for you.
Frequently asked questions
Should I use the priority attribute in the sitemap?
The priority attribute is meant for signaling the importance of your pages – more important pages can then be crawled more often. There’s one huge caveat though:
Google doesn’t take this attribute into account at all! And with Google’s market share of about 90%, it’s just not worth the effort to include them in your sitemap in most cases.
If you use a plugin that automatically includes priority attribute into the sitemap – it’s okay, but it won’t have any effect on your Google indexing or ranking.
Should the sitemap list all my pages?
There’s no need for the sitemap to include all the URLs on your website – but the leftover pages might not get found by crawlers.
It’s absolutely okay to leave out pages you are not interested in having indexed (they might get indexed anyway, use noindex directive to forbid search engines from indexing it).
Can I use sitemap to inform Google about pages I don’t want to be indexed?
Well, a sitemap won’t help you with that. A sitemap is only an aid for crawlers. Leaving a page out of the sitemap might not have any effect.
- If you don’t want your page to be crawled you need to disallow it in the robots.txt file. However, the page might still be indexed.
- If you don’t want your page to be indexed, use the noindex meta tag.
Will Google find my sitemap? Where should I place the sitemap?
The most popular way is to submit the sitemap directly in the Google Search Console. The great thing about doing it this way is that you’ll see if google checked your sitemap, how many pages it found and how many of them are currently indexed.
If for some reason you don’t want your website in GSC, or to make it easier for every possible search engine in the world to find your sitemap, you can add it to your robots.txt file (the first file a crawler visits on every website).
How to do it? It’s super easy, just add a line like this with a link to your sitemap file (or sitemap index file) to your robots.txt:
Sitemap: https://www.domain.com/sitemap-name.xml
Don’t forget that even with everything properly set, “using a sitemap doesn’t guarantee that all the items in your sitemap will be crawled and indexed.” (Source: Google)
What if I want to include more than 50,000 URLs in a sitemap?
A sitemap has an upper limit of 50,000 URLs per file. If you need to include more URLs, there’s one easy workaround:
Split your sitemap into multiple files, and include a sitemap index (basically a sitemap of sitemaps) which will point to all the “sub-sitemaps”.
<?xml version="1.0" encoding="UTF-8"?> <sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <sitemap> <loc>https://www.domain.com/post-sitemap.xml</loc> <lastmod>2019-11-06T20:19:20+00:00</lastmod> </sitemap> <sitemap> <loc>https://www.domain.com/page-sitemap.xml</loc> <lastmod>2019-10-21T18:51:43+00:00</lastmod> </sitemap> </sitemapindex>
Are there any negative effects of having multiple sitemap files and a sitemap index file?
No, not at all. Even if you are not hitting the number of URLs or filesize limits, you can still split your sitemaps into multiple files for your convenience.
As John Mueller explained in this Reddit thread: “All sitemap files of a site are imported into a common, big mixing cup, lightly shaken, and then given to Googlebot by URL in the form of an energy drink. It doesn’t matter how many files you have.”
Important things to keep in mind
- There’s nothing to lose by having a sitemap, it can only bring you benefits
- If you have a small website with hundreds of static pages, you’ll likely see little to no benefit from having a sitemap
- If you have a website with thousands of auto-generated or ever-changing pages (e.g. online shop), a sitemap can help you have your pages indexed faster, and every changed discovered and indexed faster as well
- It’s super easy to set up a sitemap with modern CMS via plugins (Yoast plugin for WordPress, etc.)
- Having a sitemap is not a ranking factor in any way
- A sitemap cannot be used to tell the search engines not to index a page
